1. 标题
· Learning Motion Representation for Real-Time Spatio-Temporal Action Localization
· 基于运动表达的实时人体动作时空定位算法
2. 成果信息
· 论文、专著、专利、软件、奖项、新闻报道的完整信息,务必使用规范的引用格式
o Zhang D, He L, Tu Z, et al. Learning Motion Representation for Real-Time Spatio-Temporal Action Localization. Pattern Recognition, 2020: 107312.
· URL: https://www.sciencedirect.com/science/article/abs/pii/S0031320320301163
· DOI: 10.1016/j.patcog.2020.107312
· CODE: https://github.com/djzgroup/RT-ST-Action-Localization
· This work was supported in part by the National Natural Science Foundation of China under Grant 61702350. It was also supported by the National Key 435 Research and Development Program of China (No. 2018YFB2100603) and the Wuhan University-Infinova project (No. 2019010019).
3. 成果团队成员
· 张德军(第一作者,通讯作者),讲师,中国地质大学(武汉)华人策略研究论坛。研究方向:人体姿态估计、目标跟踪与识别、三维场景理解。
Email: zhangdejun@cug.edu.cn
· 何霖超,硕士生,四川大学视觉合成图形图像技术国防重点学科实验室。研究方向:视频分析与理解、人体行为识别。
· 涂志刚,教授,测绘遥感信息工程国家重点实验室。研究方向:人工智能、计算机视觉、图像处理。
· 张世福,英飞拓集团研发中心总经理。研究方向:数字城市、智慧城市。
4. 成果介绍
随着计算机视觉技术与深度学习的发展,基于深度学习的人体动作(又称行为)时空定位技术也逐渐成为研究热点,并在视频监控、视频检索和人机交互等场景发挥着重要作用。行为时空定位不仅需要识别视频中的行为类别,还需要定位行为发生的时间段及对应的空间位置。当前,行为时空定位的主要难点在于:
(1)速度和精度之间的平衡关系。为获得较高的精度,通常需要引入光流场信息。然而,光流场计算的时间开销较大,难以满足实时应用的要求。
(2)边界的模糊性。行为时空定位需要预测的人体动作发生的时间段。而人体动作的边界难以界定,导致了定位精度较低。
(3)时间尺度问题。有的行为(比如:挥手)持续几秒钟,有的行为(比如:攀岩)则持续数分钟。需要考虑时间域上尺度对精度的影响。
针对上述问题,本研究提出一种基于运动表达的实时人体动作时空定位算法。首先,通过光流网络提取光流信息,并将该网络嵌入到整个模型中,实现了端到端的时空定位,并提高了模型的定位速度;其次,将时序上的运动特征和空间中的图像特征进行融合,提升了模型的特征学习能力;最后,采用多尺度特征融合方法,避免了单一特征在目标识别和位置回归时的相互影响,解决了边界的模糊性和时间尺度问题,从而提高了模型的定位精度。
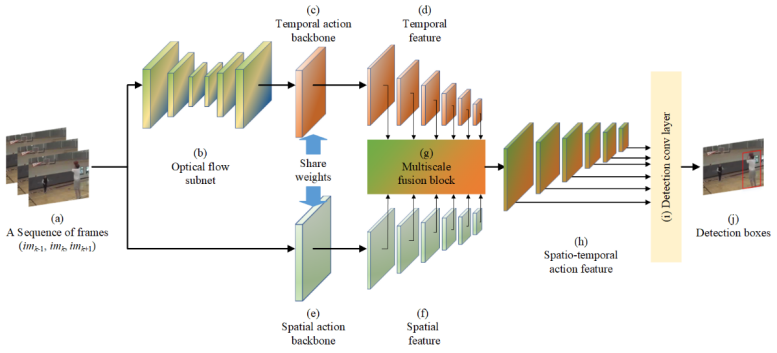
图1 基于学习的运动信息的实时的时空动作定位框架
在公开的数据集(UCF101-24、JHMDB和AVA)上进行了大量的实验,对比现有的方法,本研究在定位精度和速度上都有较为出色的表现。实验环节包括了光流网络比较、融合方式比较、行为时空定位的精度和速度比较。
在UCF101-24数据集上,本研究与现有的方法在单帧图像中的空间定位精度比较结果,如表1所示。
表1 针对数据集UCF101-24的行为空间定位精度比较

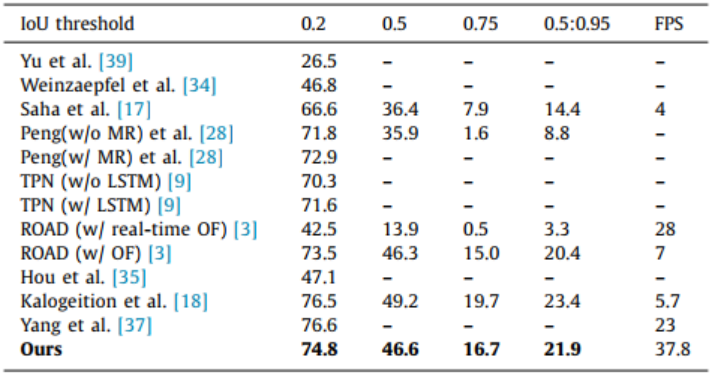
在AVA数据集上,本研究与现有的方法在定位速度方面的比较结果,如表2所示。在同等的定位精度情况下,本研究大幅度提升了定位速度,达到了实时应用的需求。
表2 针对数据集AVA的行为定位速度比较
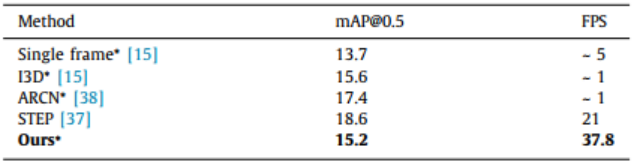
在UCF101-24数据集上,本研究与现有的方法在视频中的定位精度和速度比较结果,如表3所示。
表3针对数据集UCF101-24的行为时空定位精度与速度比较